SLM Optimization & Post-Training (GSM8k)
As part of my research into language model efficiency and capabilities, this project focuses on Small Language Models (SLMs) and their ability to perform complex math reasoning tasks, specifically evaluated on the GSM8k dataset. By adapting and fine-tuning minimal nano-scale Transformer architectures, I explored the trade-offs between model size, inference speed, and reasoning accuracy.
The Challenge: Making Small Models Smart
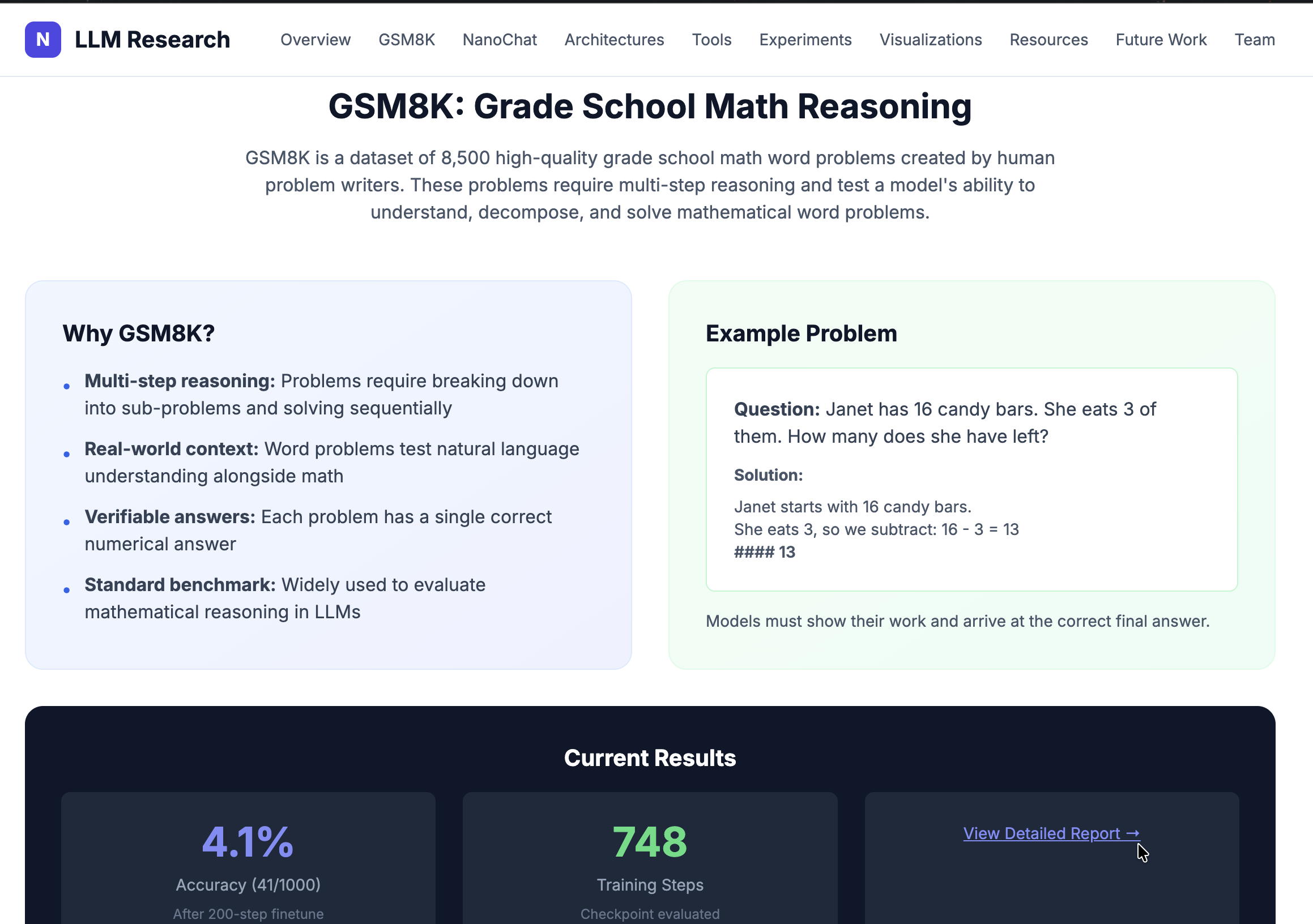
While Massive LLMs like GPT-4 dominate benchmarks, they require immense computational resources. My research aimed to see how much reasoning capability could be packed into models with just a few billion parameters. Using the GSM8k (Grade School Math 8K) dataset, the goal was to apply Post-Training and Supervised Fine-Tuning (SFT) techniques to improve the model’s zero-shot math solving abilities.
Infrastructure and Deployment
A significant portion of this project involved deploying the training and evaluation pipelines on the Rutgers Amarel High Performance Computing (HPC) cluster.
- HPC Execution: Wrote SLURM batch scripts to distribute training jobs across multiple nodes.
- Optimization: Implemented quantization and structural pruning techniques to maximize inference throughput on constrained compute environments.
- Architecture: Adapted from Andrej Karpathy’s
nanochatframework, modifying the tokenization and training loops to support custom math-focused datasets.
Results
By carefully managing the learning rate schedule and dataset mixture during mid-training and SFT, the models showed measurable improvements on the GSM8k benchmark compared to the base pre-trained checkpoints. The project demonstrated that targeted post-training can significantly elevate the domain-specific reasoning capabilities of highly constrained models.